
Yapay Zeka Modellerinde Gerçekçilik Testi: FACTS Benchmark Suite Nedir?
Google DeepMind tarafından geliştirilen FACTS Benchmark Suite, günümüz yapay zekâ sohbet botlarının gerçek hayattaki doğruluk seviyelerini ölçmek için özel olarak tasarlanmış kapsamlı bir test platformudur. Bu benzersiz benchmark, chatbotların bilgi tabanlı soruları yanıtlama, uzun metinleri analiz etme, web verilerini kullanma ve görsel yorumlama gibi farklı alanlardaki performanslarını incelemektedir.
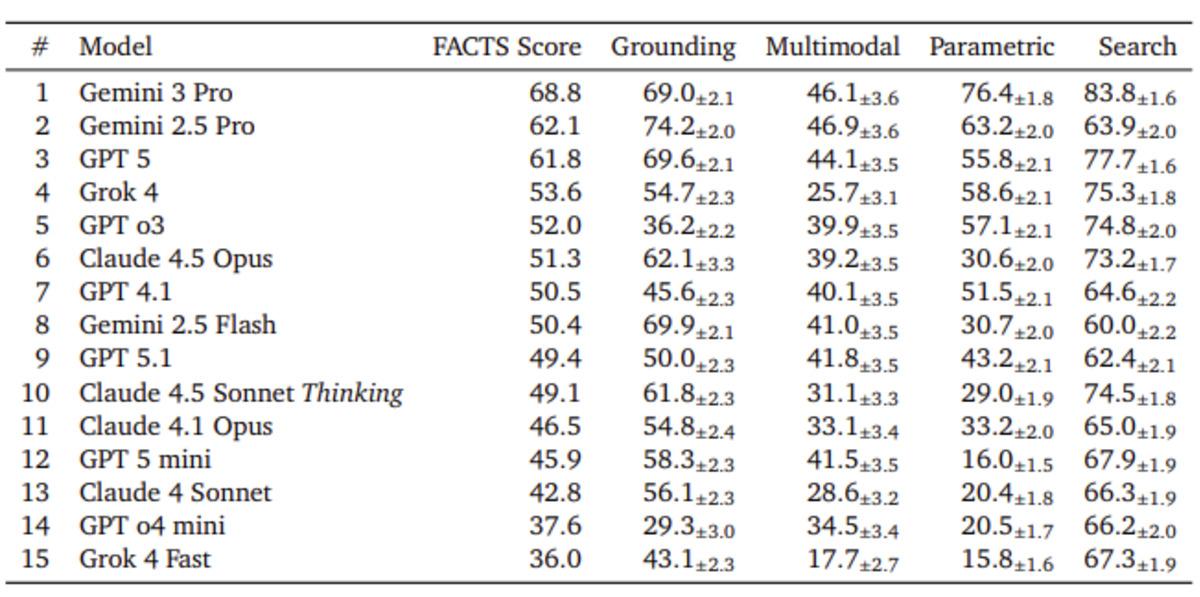
Test Kapsamı: Hangi Alanlarda Denetim Yapıldı?
FACTS Benchmark Suite, yapay zekâların çeşitli veri türleri üzerindeki doğruluk oranlarını ölçmeye odaklanır. Aşağıdaki tabloda testin kapsadığı ana başlıkları bulabilirsiniz:
| Test Alanı | Örnek Görevler |
|---|---|
| Bilgi Tabanlı Sorular | Ansiklopedik bilgi, kısa cevaplar |
| Uzun Metin Analizi | Makale özeti, metin çıkarımı |
| Web Verileri | Güncel internet bilgisi |
| Görsel Yorumlama | Resim açıklamaları, fotoğraf analizi |
Çarpıcı Sonuçlar: Üç Yanıttan Biri Yanlış!
Test sonuçları dikkat çekici düzeyde: En iyi performans gösteren yapay zekâ modelleri bile yalnızca %69 doğruluk oranına ulaşabiliyor. Bu, yapay zekâ tarafından verilen her üç cevabın en az birinin yanlış, eksik veya yanıltıcı olabileceği anlamına geliyor.
Kritik Sektörlerde Risk: Sağlık, Hukuk ve Finans
Yapay zekâ teknolojileri son yıllarda hızla hayatımıza entegre olsa da, özellikle sağlık, hukuk ve finans gibi hassas sektörlerde güvenilirlik riski taşımaya devam ediyor. Akıcı ve ikna edici yanıtlar genellikle güvenilir veriyle karıştırılsa da, bu algoritmaların verdiği bilgiler her zaman doğru olmayabiliyor. Yanıltıcı, eksik veya yanlış bilgi paylaşımı, kritik alanlarda önemli sonuçlar doğurabilir.
Yapay Zekâda “Halüsinasyon” Sorunu
Geçmişte de sıkça gündeme gelen halüsinasyon (yanlış veya uydurma cevap üretimi) problemi, FACTS Benchmark Suite sayesinde tekrar gözler önüne serildi. AI modellerinin gerçeğe dayalı olmayan veya tamamen yanlış bilgiler üretmesi, güven sorununun temel nedenlerinden biri olarak öne çıkıyor.
Uzman Görüşleri: İnsan Denetimi Olmadan Güven Mümkün Mü?
Google DeepMind’ın bu çalışması, yapay zekâmızın kısa bir vadede insan denetimi olmadan tam güvenilir bir bilgi kaynağına dönüşmesinin zor olacağını bir kez daha kanıtlıyor. Uzmanlar, yapay zekânın güçlü bir yardımcı olmaya devam edeceğini, ancak insan gözetimi ihmal edildiğinde hata payının yüksek olacağını vurguluyorlar.
Yapay Zekâ Yanıtlarının Doğruluğu Tablosu
| Model | Doğruluk Oranı | Yanlış/İkna Edici Yanıt Yüzdesi |
|---|---|---|
| Lider Model A | %69 | %31 |
| Ortalama Model B | %60 | %40 |
| Gelişen Model C | %54 | %46 |
Sonuç ve Öneriler
Yapay zekâ sohbet botları yakın gelecekte gündelik işlerimizde yardımcı olmaya devam edecek. Ancak özellikle hassas sektörlerde insan denetiminin önemi giderek artacak. Kullanıcıların, yapay zekâ yanıtlarının doğruluk payını sorgulaması ve kritik kararlar için her zaman uzman görüşüne başvurması önerilmektedir.




