
Yapay Zekâ ve Bilimsel Muhakemede Yeni Dönem: FrontierScience Nedir?
OpenAI, yapay zekâ modellerinin bilim insanlarıyla karşılaştırılabilecek seviyede muhakeme ve akıl yürütme becerilerini ölçmek için FrontierScience adlı yeni bir test platformu geliştirdiğini duyurdu. Bu yenilikçi kıyaslama, GPT-5.2 ve Gemini 3 Pro gibi en güçlü yapay zekâ modellerinin bilimsel zorlukları nasıl karşıladığını somut verilerle gösteriyor.
Geleneksel testlerin, günümüzün süper güçlü yapay zekâ modelleri için yetersiz kalmaya başlamasıyla, OpenAI sektör için yeni, uzman seviyesinde bir sınav hazırlama ihtiyacı hissetti. FrontierScience ile hedef, yalnızca teori bilgisi değil; aynı zamanda zor bilimsel problemleri çözme, mantık yürütme ve araştırmacı süreçlerine entegrasyon yeteneklerini ölçmek.

FrontierScience Testinin Amacı ve Neden Gerekliliği?
FrontierScience, yapay zekâların fizik, kimya ve biyoloji konularında uzman bilimsel muhakeme kabiliyetlerini irdeleyen yenilikçi bir standart oluşturuyor. OpenAI, bu aracı geliştirirken uluslararası bilim olimpiyatlarında madalya kazanmış uzmanlarla ve doktoralı bilim insanlarıyla birlikte çalıştı.
Klasik testlerde genellikle çoktan seçmeli sorulara odaklanılırken, FrontierScience farklı bir yaklaşım benimseyerek modellerin karmaşık bilimsel gereksinimleri karşılayıp karşılamadığını analiz ediyor. Amaç yalnızca bilgi seviyesini ölçmek değil, aynı zamanda modellenin problem çözme yöntemlerini ve araştırmacılarla iş birliği potansiyelini değerlendirmek.

FrontierScience Testinde İki Ana Kategori: Olimpiyat ve Araştırma Modülü
| Kategori | Açıklama | Soru Tipi | Değerlendirme |
|---|---|---|---|
| Olimpiyat | Uluslararası bilim olimpiyatı madalyalı uzmanlar tarafından hazırlanmış kısa yanıtlı sorular | 100 kısa cevap – teorik bilgi ve analitik düşünce | Doğru/yanlış ve mantıksal çözüm |
| Araştırma | Doktora seviyesinde bilim insanlarının özgün araştırma görevleri | 60 açık uçlu – pratik ve özgün araştırma senaryoları | 10 puanlı rubrik sistemi (detaylı değerlendirme) |
Olimpiyat Testi teorik bilgiyi ve üst düzey çözümleme kabiliyetlerini ölçerken, Araştırma Testi bilimsel problem çözme ve hipotetik düşünceyi zorluyor. Özellikle ikinci bölümde, modeller sıfırdan bir hipotez oluşturup bunu bilimsel sürece dökmek zorunda kalıyor.
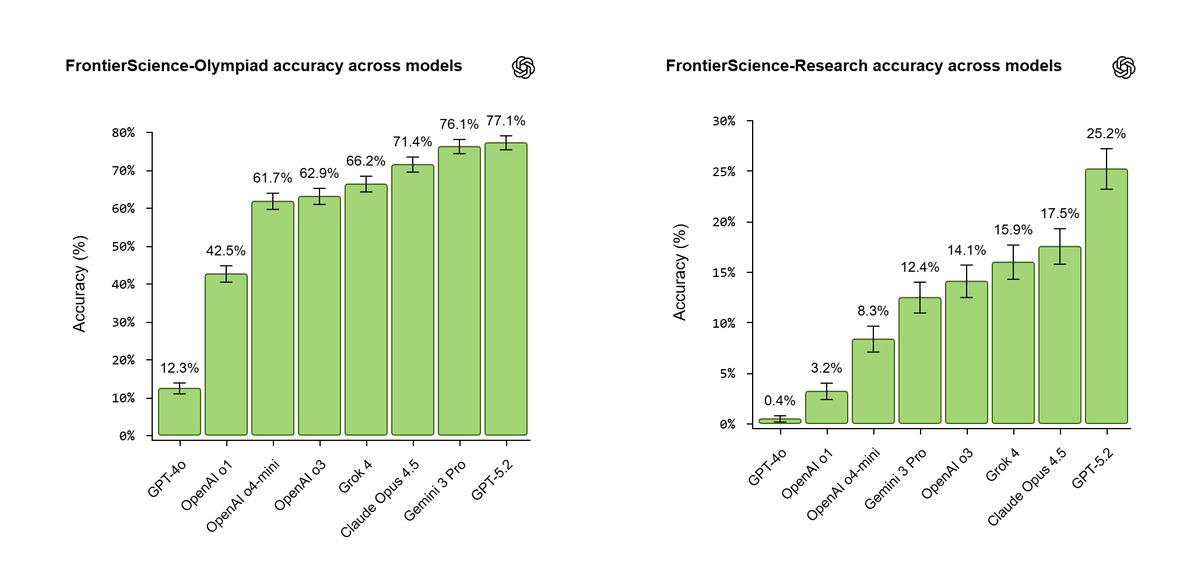
En Güçlü Modellerin Karşılaşması: GPT-5.2 ve Gemini 3 Pro Sonuçları
OpenAI, FrontierScience ile GPT-5.2 ve Gemini 3 Pro dahil piyasadaki en güçlü yapay zekâ modellerinin performansını ölçtü. Sonuçlar çarpıcı:
| Model | Olimpiyat Başarı (%) | Araştırma Başarı (%) |
|---|---|---|
| GPT-5.2 | 77 | 25 |
| Gemini 3 Pro | 76 | Düşük (spesifik veri yok) |
Tablodan da görüleceği üzere, GPT-5.2 hem Olimpiyat hem de Araştırma alanında liderliği elde tutuyor. Özellikle Olimpiyat sorularında yüzde 77’lik başarıya ulaşırken, açık uçlu Araştırma görevlerinde ise yüzde 25’lik bir başarı oranı yakaladı. Gemini 3 Pro ise Olimpiyat performansında çok yakın sonuçlar üretse de, özgün araştırma görevlerinde yapay zekâ modelleri genel olarak zorluk yaşadı.

Analiz: Yapay Zekânın Bilimsel Muhakeme Sınırları Neler?
Sonuçlar gösteriyor ki, yapay zekâ modelleri kitaplarda yazan akademik ve teorik problemleri çözme konusunda neredeyse uzman insanlarla yarışabilecek seviyeye ulaştı. Fakat iş, sıfırdan özgün hipotez üretmeye, bilimsel yöntemle yeni çözüm yolları bulmaya geldiğinde, henüz insan zekâsına ve denetimine duyulan ihtiyaç ortadan kalkmış değil.
FrontierScience, yapay zekâ gelişiminin gerçek sınırlarını görmek ve modellerin gelecekte bilim dünyasında ne kadar rol oynayabileceklerini anlamak için sektöre yön veren bir “kuzey yıldızı” niteliğinde.
SEO Dostu Sonuç: FrontierScience ile Yapay Zekâ ve Bilimsel Araştırma Performansı
Bu yeni test platformu, arama motorlarında “OpenAI FrontierScience nedir?”, “GPT-5.2 bilimsel test sonuçları”, “Gemini 3 Pro araştırma performansı” gibi sorgular için özgün, uzun ve detaylı içerik sunmanın anahtarıdır. Bilimsel yapay zekâ uygulamalarına ilgisi olan akademisyenler, teknoloji meraklıları ve sektör profesyonelleri için, FrontierScience gelişmeleri takip etmek büyük avantaj sağlayacaktır.
Daha fazla gelişme, güncel test sonuçları ve model karşılaştırmaları için bizi takip etmeye devam edin!




